

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
§管理資料庫演化
當您使用關聯式資料庫時,您需要一種方法來追蹤和整理您的資料庫結構演化。通常有幾種情況需要您使用更精密的技術來追蹤資料庫結構變更
- 當您在開發人員團隊中工作時,每個人都需要知道任何結構變更。
- 當您在生產伺服器上部署時,您需要有穩健的方法來升級資料庫結構。
- 如果您在多台機器上工作,您需要讓所有資料庫結構保持同步。
§啟用演化
將 evolutions 和 jdbc 加入您的相依性清單中。例如,在 build.sbt 中
libraryDependencies ++= Seq(evolutions, jdbc)
§使用編譯時 DI 執行演化
如果您使用 編譯時相依性注入,您需要將 EvolutionsComponents 特質混入您的 cake 中,以存取 ApplicationEvolutions,它會在實例化時執行演化。EvolutionsComponents 需要定義 dbApi,您可以透過混入 DBComponents 和 HikariCPComponents 來取得。由於 applicationEvolutions 是由 EvolutionsComponents 提供的 lazy val,您需要存取該 val 以確保執行演化。例如,您可以在 ApplicationLoader 中明確存取它,或從其他元件建立明確的相依性。
您的模型需要 Database 的實例才能連線到您的資料庫,這可以從 dbApi.database 取得。
import play.api.db.evolutions.EvolutionsComponents
import play.api.db.DBComponents
import play.api.db.Database
import play.api.db.HikariCPComponents
import play.api.routing.Router
import play.api.ApplicationLoader.Context
import play.api.BuiltInComponentsFromContext
import play.filters.HttpFiltersComponents
class AppComponents(cntx: Context)
extends BuiltInComponentsFromContext(cntx)
with DBComponents
with EvolutionsComponents
with HikariCPComponents
with HttpFiltersComponents {
// this will actually run the database migrations on startup
applicationEvolutions
}§演化指令碼
Play 使用多個演化指令碼追蹤您的資料庫演化。這些指令碼以純粹的 SQL 編寫,而且預設應位於您應用程式的 conf/evolutions/{資料庫名稱} 目錄中。如果演化套用於您的預設資料庫,這個路徑為 conf/evolutions/default。
第一個指令碼命名為 1.sql,第二個指令碼命名為 2.sql,以此類推…
每個指令碼包含兩個部分
- Ups 部分描述必要的轉換。
- Downs 部分描述如何還原它們。
例如,看看這個啟動基本應用程式的第一個演化指令碼
-- Users schema
-- !Ups
CREATE TABLE User (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
password varchar(255) NOT NULL,
fullname varchar(255) NOT NULL,
isAdmin boolean NOT NULL,
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE User;
Ups 和 Downs 部分使用標準的單行 SQL 註解區分,分別包含 !Ups 或 !Downs。SQL92 (--) 和 MySQL (#) 註解樣式都受支援,但我們建議使用 SQL92 語法,因為它受更多資料庫支援。
Play 會將你的
.sql檔案分割成一系列以分號分隔的陳述式,然後逐一對資料庫執行。因此,如果你需要在陳述式內使用分號,請輸入;;取代;來跳脫。例如,INSERT INTO punctuation(name, character) VALUES ('semicolon', ';;');。
如果在 application.conf 中設定了資料庫且存在演化腳本,則會自動啟用演化。你可以透過設定 play.evolutions.enabled=false 來停用它們。例如,當測試設定自己的資料庫時,你可以為測試環境停用演化。
當演化啟用時,Play 會在開發模式中的每次要求之前,或在生產模式中啟動應用程式之前,檢查你的資料庫架構狀態。在開發模式中,如果你的資料庫架構不是最新版本,錯誤頁面會建議你透過執行適當的 SQL 腳本來同步你的資料庫架構。
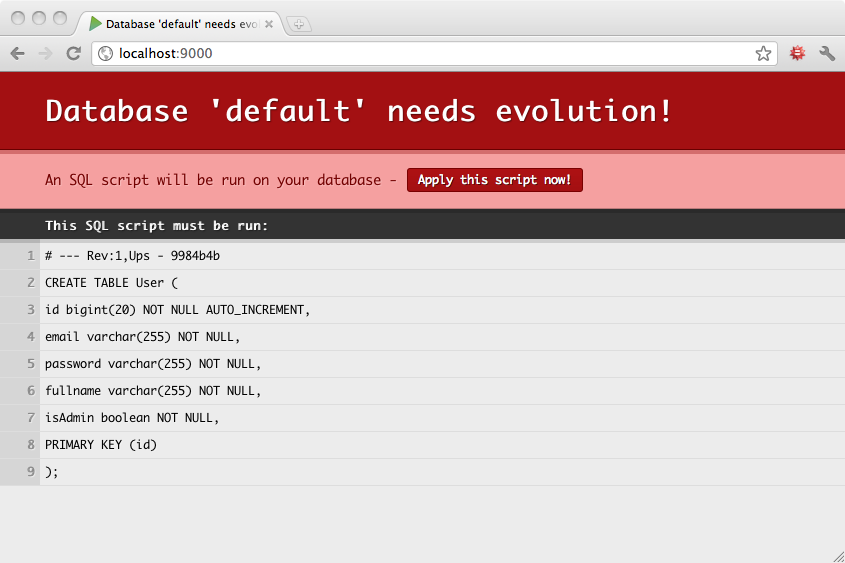
如果你同意 SQL 腳本,你可以按一下「套用演化」按鈕直接套用它。
§演化設定
演化可以在全域和每個資料來源中設定。對於全域設定,金鑰應以 play.evolutions 為前綴。對於每個資料來源設定,金鑰應以 play.evolutions.db.<datasourcename> 為前綴,例如 play.evolutions.db.default。支援下列設定選項
enabled- 是否啟用演化。如果全域設定為 false,則會完全停用演化模組。預設為 true。schema- 將儲存已產生演化和鎖定表的資料庫架構。預設未設定架構。metaTable- 儲存演化元資料的表格。預設為play_evolutions。autocommit- 是否應使用自動提交。如果為 false,將在單一交易中套用演化。預設為 true。useLocks- 是否應使用鎖定表格。如果您有許多潛在會執行演化的 Play 節點,但您想要確保只有一個節點執行,就必須使用此選項。它會建立一個表格,名稱與您的演化元資料表格相同,並加上_lock字尾(預設為play_evolutions_lock),並使用SELECT FOR UPDATE NOWAIT或SELECT FOR UPDATE來鎖定它。這只會在 Postgres、Oracle 和 MySQL InnoDB 中運作。它不會在其他資料庫中運作。預設為 false。autoApply- 是否應自動套用演化。在開發模式中,這會導致自動套用向上和向下演化。在生產模式中,這會導致只自動套用向上演化。預設為 false。autoApplyDowns- 是否應自動套用向下演化。在生產模式中,這會導致自動套用向下演化。在開發模式中沒有作用。預設為 false。path- 類別路徑或檔案系統中演化腳本的路徑。預設為evolutions。請參閱「演化腳本的位置」。substitutions.mappings- 變數(沒有字首和字尾)與其替換項的對應。預設沒有設定對應。請參閱「變數替換」。substitutions.prefix- 置放符號語法使用的字首。預設為$evolutions{{{。請參閱「變數替換」。substitutions.suffix- 置放符號語法使用的字尾。預設為}}}。請參閱「變數替換」。substitutions.escapeEnabled- 是否啟用透過語法!$evolutions{{{...}}}逃逸變數。預設為true。請參閱「變數替換」。
例如,若要為所有演化啟用 autoApply,您可以在 application.conf 或系統屬性中設定 play.evolutions.autoApply=true。若要停用名為 default 的資料來源的自動提交,請設定 play.evolutions.db.default.autocommit=false。
§演化腳本的位置
如前所述,預設情況下,進化腳本位於應用程式的 conf/evolutions/{資料庫名稱} 目錄中。但是,您可以變更資料夾的名稱:例如,如果您想將預設資料庫的腳本儲存在 conf/db_migration/default 中,您可以透過設定 path 設定檔來執行此操作
# For the default database
play.evolutions.db.default.path = "db_migration"
# Or, if you want to set the location for all databases
play.evolutions.db.path = "db_migration"
Play 永遠可以載入這些腳本,因為 conf 資料夾的內容在開發模式和 生產模式 中都位於類別路徑中。
您也可以將進化腳本儲存在專案資料夾外部,並使用絕對路徑或相對路徑來參照它們
# Absolute path:
play.evolutions.db.default.path = "/opt/db_migration"
# Relative path (as seen from your project's root folder)
play.evolutions.db.default.path = "../db_migration"
但是,請注意,當使用此類設定檔時,如果您決定組合一個,進化腳本將不會包含在生產套件中,因此您必須在生產中管理進化腳本。
最後,您可以將進化腳本儲存在專案中,但位於 conf 資料夾外部
play.evolutions.db.default.path = "./db_migration"
在這種情況下,腳本將不會位於類別路徑中。在開發過程中,這並不重要,因為在類別路徑中尋找進化腳本之前,Play 會在檔案系統中尋找它們(這就是上述絕對路徑和相對路徑方法可行的原因)。
但是,不將進化資料夾放在 conf 目錄中,因此也不在類別路徑中,表示它不會打包用於生產。因此,為了確保資料夾已打包並在生產中可用,您必須在 build.sbt 中設定它
Universal / mappings ++= (baseDirectory.value / "db_migration" ** "*").get.map {
(f: File) => f -> f.relativeTo(baseDirectory.value).get.toString
}
§變數替換
您可以在進化腳本中定義將以其替換項取代的佔位符,這些替換項定義在 application.conf 中
play.evolutions.db.default.substitutions.mappings = {
table = "users"
name = "John"
}
像這樣的進化腳本
INSERT INTO $evolutions{{{table}}}(username) VALUES ('$evolutions{{{name}}}');
現在將變成
INSERT INTO users(username) VALUES ('John');
在套用進化時。
進化元資料表將包含原始 SQL 腳本,不 會替換佔位符。
變數替換區分大小寫,因此 $evolutions{{{NAME}}} 與 $evolutions{{{name}}} 相同。
您也可以變更佔位符語法的字首和字尾
# Change syntax to @{...}
play.evolutions.db.default.substitutions.prefix = "@{"
play.evolutions.db.default.substitutions.suffix = "}"
evolution 模組也支援跳脫,適用於不應替換變數的情況。此跳脫機制預設為啟用。若要停用,您需要設定
play.evolutions.db.default.substitutions.escapeEnabled = false
如果啟用,語法 !$evolutions{{{...}}} 可用於跳脫變數替換。例如
INSERT INTO notes(comment) VALUES ('!$evolutions{{{comment}}}');
不會以其替換項取代,而是會變成
INSERT INTO notes(comment) VALUES ('$evolutions{{{comment}}}');
在最後的 sql 中。
此跳脫機制將套用至所有
!$evolutions{{{...}}}佔位符,無論是否在substitutions.mappings設定檔中定義變數的對應。
§同步並行變更
現在讓我們假設有兩位開發人員處理這個專案。Jamie 將處理需要新增資料庫表格的功能。因此 Jamie 將建立下列 2.sql evolution 腳本
-- Add Post
-- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE Post;
Play 會將此 evolution 腳本套用至 Jamie 的資料庫。
另一方面,Robin 將處理需要變更 User 表格的功能。因此 Robin 也會建立下列 2.sql evolution 腳本
-- Update User
-- !Ups
ALTER TABLE User ADD age INT;
-- !Downs
ALTER TABLE User DROP age;
Robin 完成功能並提交(假設使用 Git)。現在 Jamie 必須在繼續之前合併 Robin 的工作,因此 Jamie 執行 git pull,而合併發生衝突,如下所示
Auto-merging db/evolutions/2.sql
CONFLICT (add/add): Merge conflict in db/evolutions/2.sql
Automatic merge failed; fix conflicts and then commit the result.
每位開發人員都建立一個 2.sql evolution 腳本。因此 Jamie 需要合併此檔案的內容
<<<<<<< HEAD
-- Add Post
-- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
DROP TABLE Post;
=======
-- Update User
-- !Ups
ALTER TABLE User ADD age INT;
-- !Downs
ALTER TABLE User DROP age;
>>>>>>> devB
合併非常容易
-- Add Post and update User
-- !Ups
ALTER TABLE User ADD age INT;
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
-- !Downs
ALTER TABLE User DROP age;
DROP TABLE Post;
此 evolution 腳本代表資料庫的新版次 2,與 Jamie 已套用的前一版次 2 不同。
因此 Play 會偵測它並要求 Jamie 同步資料庫,方法是先還原已套用的舊版次 2,再套用新版次 2 腳本
§不一致狀態
有時您會在演化腳本中犯錯,而它們會失敗。在這種情況下,Play 會將您的資料庫架構標記為不一致狀態,並要求您在繼續之前手動解決問題。
例如,此演化的 Ups 腳本有錯誤
-- Add another column to User
-- !Ups
ALTER TABLE Userxxx ADD company varchar(255);
-- !Downs
ALTER TABLE User DROP company;
因此嘗試套用此演化會失敗,而 Play 會將您的資料庫架構標記為不一致
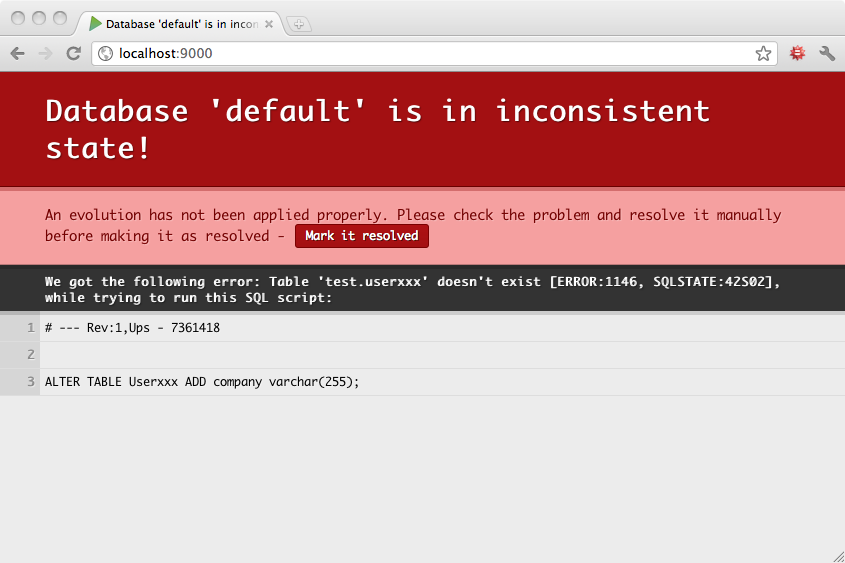
現在在繼續之前,您必須修正此不一致。因此,您執行已修正的 SQL 指令
ALTER TABLE User ADD company varchar(255);
… 然後按一下按鈕將此問題標記為手動解決。
但是由於您的演化腳本有錯誤,您可能想要修正它。因此,您修改 3.sql 腳本
-- Add another column to User
-- !Ups
ALTER TABLE User ADD company varchar(255);
-- !Downs
ALTER TABLE User DROP company;
Play 會偵測到這個取代先前 3 個的全新演化,並執行適當的腳本。現在一切都已修正,您可以繼續工作。
不過,在開發模式中,通常更簡單的方法是直接刪除您的開發資料庫,並從頭重新套用所有演化。
§交易性 DDL
預設情況下,每個演化腳本的每個陳述式都會立即執行。如果您的資料庫支援 交易性 DDL,您可以在 application.conf 中設定 evolutions.autocommit=false 以變更此行為,導致 **所有** 陳述式僅在 **一個交易** 中執行。現在,當演化腳本無法在停用自動提交的情況下套用時,整個交易會回滾,且不會套用任何變更。因此,您的資料庫會保持「乾淨」,且不會變得不一致。這讓您能輕鬆修正演化腳本中的任何 DDL 問題,而無需像上述那樣手動修改資料庫。
§演化儲存和限制
演進會儲存在資料庫中名為 play_evolutions 的表格中。文字欄位會儲存實際的演進腳本。您的資料庫在文字欄位上可能有限制 64kb 的大小。若要解決 64kb 的限制,您可以:手動變更 play_evolutions 表格結構,變更欄位類型,或(建議)建立多個小於 64kb 的演進腳本。
下一步:伺服器後端
在此文件檔中發現錯誤?此頁面的原始程式碼可以在 這裡 找到。在閱讀完 文件檔指南 後,請隨時提交拉取請求。有任何問題或建議想分享?請前往 我們的社群論壇,與社群展開討論。